ブログ
これまでに経験してきたプロジェクトで気になる技術の情報を紹介していきます。
AI の機械学習アルゴリズム(LightGBM)を使って、ガチャ結果を予測してみた
 T, M
11 months
T, M
11 months

昨今、AI で過去データを元に、さまざまな事柄を予測しています。
その用途は広く天気予報はしかり、果ては株価や競馬まで幅広く使われています。
そこでふと頭に浮かびました。
・・・AI を使ってガチャの排出結果を予測できないだろうか?

──という訳で、今回は python と AI の機械学習アルゴリズム LightGBM を使用してガチャの排出結果を予測していきます。
環境について
今回使用するパッケージと、環境構築の方法は下記となります。
使用パッケージ
| パッケージ名 | パッケージの説明 | 使用用途 |
|---|---|---|
| lightgbm | Microsoftが開発した機械学習フレームワーク | AI の学習モデル作成や予測を行うのに使用 |
| sklearn | Pythonで利用できるオープンソースの機械学習パッケージ | 学習データの分割に使用 |
| pandas | Pythonでデータ分析を行うためのパッケージ | 表形式の DataFrame を扱うのに使用 |
| numpy | Pythonで数値計算を効率的に行うためのパッケージ | 配列情報の切り出しに使用 |
| csv | PythonでCSVファイルの読み書きを行うための標準パッケージ | ガチャ結果CSVファイルの読込みに使用 |
| Jupyter Notebook | Webブラウザ上でPythonなどのコードを実行・編集できるツール | 必須ではありませんが、PG実行や結果確認で使用 |
環境構築
# 仮想環境の作成 PS> python -m venv .venv # 仮想環境の有効化 PS> .\.venv\Scripts\activate (.venv) PS> # 使用パッケージ(lightgbm、sklearn、pandas、numpy)のインストール ※CSVは標準なので不要 (.venv) PS> pip install lightgbm sklearn pandas numpy # 任意で Jupyter Notebook のインストール (.venv) PS> python -m pip install notebook
ガチャ結果予測の概要について
今回のブログの大まかな流れは下記となります。
1.検証用ガチャの作成
検証用のガチャを作成します。
学習データを作成するために、排出結果をCSVファイルに出力するようにしておきます。
2.学習データの作成
AI の頭脳を形成するための元となる学習データを作成します。
学習データは基本的に「答え」と「答えを形成する情報」で1セットとなります。
今回の場合は下記のようになります。
答え :ガチャの排出結果 答えを形成する情報:直近の10回分のガチャの排出結果 ※専門用語で特徴量ともいいます。
学習データはある程度の件数が必要となります。
※今回は 10000 件程度の学習データを用意しています。
3.AI の学習モデルの構築
AI の機械学習アルゴリズム(LightGBM)に用意した学習データを読み込ませ、回帰型モデルを構築します。
回帰型モデルとは、連続した要因を分析して将来に発生する現象を予測する分析モデルとなります。
今回のような、過去の履歴から未来を予測する場合によく使われるモデルとなります。
4.予測元となるデータの作成
予測元となるデータは「答えを形成する情報」となります。
今回の場合は、直近の10回分のガチャの排出結果となります。
5.予測の実行と確認
構築した学習モデルに、予測元となるデータを与えて、排出されるガチャ結果を予測させます。
予測完了後にはガチャを実行し、実際の排出結果と予測結果が一致するかを確認します。
1.検証用ガチャの作成
基本的にソーシャルゲームによくある、重みをつかった2段階抽選を行うガチャを作成します。
具体的には最初に「Rarity」を抽選し、次に抽選された「Rarity」に該当するロット一覧から最終的な商品の「Id」を抽選する形式です。
※今回はガチャの排出結果の予測がメインとなるため、検証用に作ったガチャの抽選ロジックは省略いたします。
今回使用する検証用ガチャのロットと、排出結果の出力CSVファイルは下記となります。
【ガチャのロット】
ロット毎にそれぞれ ID、レアリティ、重み、商品名(Label)を設定したデータとなります。
重み(Weight)は抽選のしやすさを表し、値が大きければ大きい程抽選確率が上がります。
使用するガチャは2段階抽選を行うため、レアリティと抽選品の2種類のロットデータを設定しています。
# ------------------------------------------------------------
# ガチャのロット
# ------------------------------------------------------------
# 1段階抽選ロット [Id, Rarity, Weight, Label]
lot_1st_list = [
[ 1, 1, 79, 'R'], # 抽選率 79%
[ 2, 2, 15, 'SR'], # 抽選率 15%
[ 3, 3, 6, 'SSR'], # 抽選率 6%
]
# 2段階抽選ロット [Id, Rarity, Weight, Label]
lot_2nd_all_list = [
[ 1, 1, 100, '剣:クレイモア'],
[ 2, 1, 100, '短剣:ファイアバゼラード'],
[ 3, 1, 100, '槍:クーゼ'],
[ 4, 1, 100, '斧:傭兵の斧'],
[ 5, 1, 100, '杖:松明'],
[ 6, 1, 100, '銃:グレネード'],
[ 7, 1, 100, '格闘:パタ'],
[ 8, 1, 100, '弓:コンポジットボウ'],
[ 9, 1, 100, '楽器:ラミアの竪琴'],
[ 10, 1, 100, '刀:霊銀刀'],
[ 11, 1, 100, '剣:アネラス'],
[ 12, 1, 100, '短剣:割れた酒瓶'],
[ 13, 1, 100, '槍:ファイアグレイブ'],
[ 14, 1, 100, '斧:アイアンペンチ'],
[ 15, 1, 100, '杖:宿樹の仙杖'],
[ 16, 1, 100, '銃:マッチロック'],
[ 17, 1, 100, '格闘:ヒートパタ'],
[ 18, 1, 100, '弓:ミスリルボウ'],
[ 19, 1, 100, '楽器:ナイトベル'],
[ 20, 1, 100, '刀:木刀'],
[ 21, 2, 100, '剣:タンザナイトソード・ミコー'],
[ 22, 2, 100, '短剣:絆の短剣'],
[ 23, 2, 100, '槍:レイジングハルバード'],
[ 24, 2, 100, '斧:マッシヴアクス'],
[ 25, 2, 100, '杖:魔女の箒'],
[ 26, 2, 100, '銃:ピーシーズ'],
[ 27, 2, 100, '格闘:グレートタロン'],
[ 28, 2, 100, '弓:インペリアルボウ'],
[ 29, 2, 100, '楽器:マルメテル・カナデテミル'],
[ 30, 2, 100, '刀:彷徨の刃'],
[ 31, 3, 100, '剣:オメガスウォード'],
[ 32, 3, 100, '短剣:オメガバゼラード'],
[ 33, 3, 100, '槍:オメガバルーチャ'],
[ 34, 3, 100, '斧:オメガファルシャ'],
[ 35, 3, 100, '杖:オメガロッド'],
[ 36, 3, 100, '銃:オメガシューター'],
[ 37, 3, 100, '格闘:オメガクロー'],
[ 38, 3, 100, '弓:オメガボウ'],
[ 39, 3, 100, '楽器:オメガストリング'],
[ 40, 3, 100, '刀:オメガブレイド'],
]
【ガチャ結果CSV(gacha_result.csv)】
ガチャを実行した時の排出結果のレアリティとIDを記録したものとなります。
Rarity,Id 1,1 1,12 1,4 1,14 2,26 1,4 1,3 1,16 ・・・ 省略
2.学習データの作成
機械学習の AI の学習モデルを作るタネとなる学習データの作成を行います。
まずはCSVファイルの読込む下記メソッド(load_gacha_result_df)にて、ガチャ結果CSVファイルをDataFrame形式に変換します。
【読込処理】
import csv
import pandas as pd
# ------------------------------------------------------------
# ガチャ結果を DataFrame に読込
# ------------------------------------------------------------
def load_gacha_result_df(file_path):
# ガチャ抽選結果CSVファイルの読込
with open(file_path, newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
data = [row for row in reader]
# ヘッダとデータを分割
header = data[0]
data = data[1:]
# DataFrameに変換
df = pd.DataFrame(data, columns=header)
# 全てまとめて数字に変換
df = df.apply(pd.to_numeric, errors='coerce').fillna(0).astype(int)
return df
# ------------------------------------------------------------
# 動作確認
# ------------------------------------------------------------
# ガチャ抽選結果CSVファイルのPath設定
file_path = 'data/gacha_result.csv'
# ガチャ結果を DataFrame に読込
gacha_result_df = load_gacha_result_df(file_path)
# 内容確認 ※処理結果を参照
display(gacha_result_df)
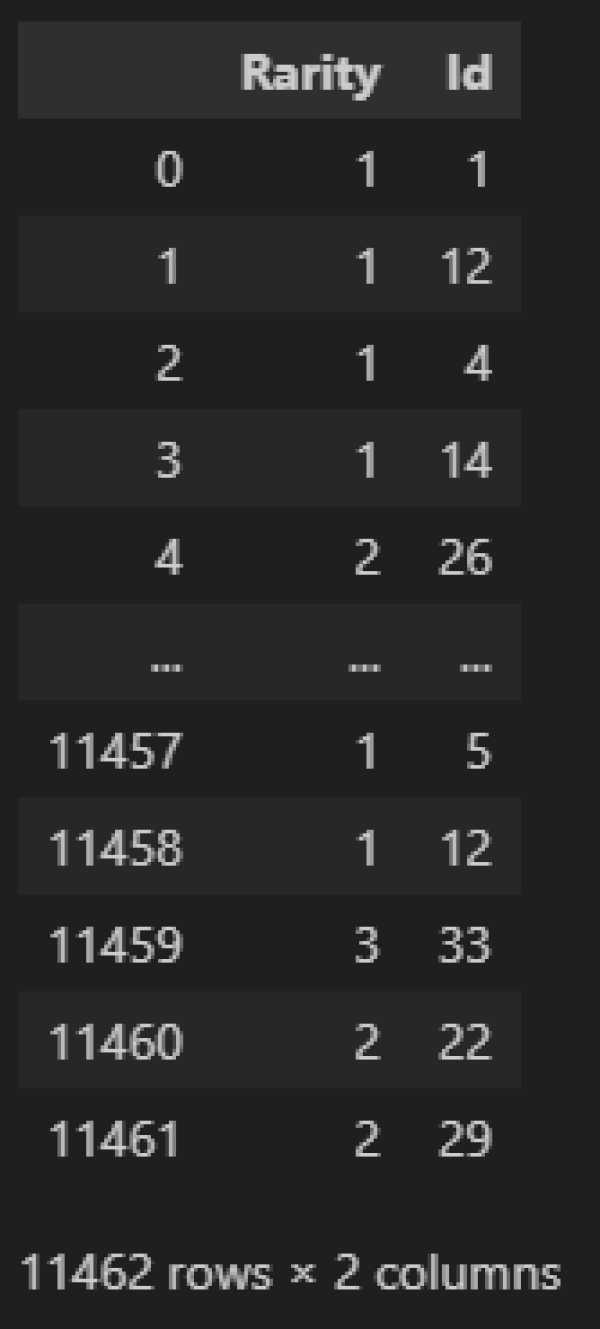
正常に処理されれば、ガチャ結果が下記のような DataFrame になります。
※ここの「Rarity」はガチャ結果のレアリティで、「Id」がガチャ結果のIDとなります。
【処理結果】
次に学習データを作成する下記メソッド(create_hist_header、create_learn_df)にて、学習データの形式の DataFrame に加工します。
具体的には、「答え(ガチャ結果)」と「答えを形成する情報(直近10回分のガチャ結果)」で1レコードとなる形式に加工していきます。
【加工処理】
# ------------------------------------------------------------
# 抽選結果履歴ヘッダの作成
# ------------------------------------------------------------
def create_hist_header(hist_num):
return [f"Bef_{i}_Result" for i in range(1, hist_num + 1)]
# ------------------------------------------------------------
# 学習データ形式の DataFrame に加工
# target :参照するカラム名
# hist_num:参照する直近の履歴数
# ------------------------------------------------------------
def create_learn_df(data_df, target, hist_num):
# 学習データの初期化
learn_list = [] # 学習データ
# 学習データ1レコードのデータ件数 ※抽選結果+抽選結果の履歴数
learn_col_num = hist_num + 1
# 学習データのヘッダ情報を作成 ※抽選結果+抽選結果履歴
learn_header = ["Result"] + create_hist_header(hist_num)
# 抽選結果のデータを抽出
data_df = data_df[target]
# 学習データ用に抽選結果と直近の抽選結果の履歴を取得
for i in range(learn_col_num, len(data_df)):
learn_list.append(data_df[i - learn_col_num:i][::-1].tolist())
# 学習データのDataFrame化
learn_df = pd.DataFrame(learn_list, columns=learn_header)
return learn_df
# ------------------------------------------------------------
# 動作確認
# ------------------------------------------------------------
# ガチャ抽選結果CSVファイルのPath設定
file_path = 'data/gacha_result.csv'
# ガチャ結果を DataFrame に読込
gacha_result_df = load_gacha_result_df(file_path)
# 学習データ形式の DataFrame に加工
learn_df = create_learn_df(gacha_result_df, "Id", 10) ★追加
# 内容確認 ※処理結果を参照
display(learn_df)
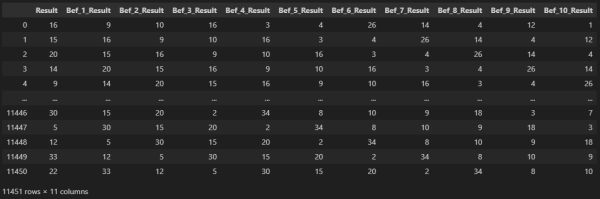
正常に処理されれば、読込んだガチャ結果が下記のような DataFrame になります。
※ここの「Result」はガチャ結果の ID で、「Bef_[N]_Result」が 直近 N 回前のガチャ結果の ID となります。
【処理結果】
3.AI の学習モデルの構築
学習モデルを作成する下記メソッド(create_learn_model)にて、作成した学習データから AI の頭脳となる学習モデルを作成します。
作成する学習モデルは、機械学習アルゴリズム LightGBM の「回帰モデル」という形式のモデルとなります。
これは連続した値を元に、次の値を予測するモデルです。
※学習モデル作成時の LGBMRegressor の設定値は、筆者が確認した範囲内で最も過学習が少なかった設定値となります。
調整次第でもっと良い結果となる可能性もありますので、その点はご理解お願いいたします。
【モデル作成処理】
import lightgbm as lgb
from lightgbm import LGBMRegressor
from lightgbm import early_stopping
from sklearn.model_selection import train_test_split
# ------------------------------------------------------------
# 学習モデルを作成
# ------------------------------------------------------------
def create_learn_model(learn_df):
# 学習データを特徴値と目的値に分割
X_df = learn_df.drop(columns="Result")
y_df = learn_df["Result"]
# データの分割
X_train, X_test, y_train, y_test = train_test_split(
X_df, y_df, test_size=0.2, random_state=42
)
# 回帰モデルで学習
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# モデルのインスタンスを作成
model = LGBMRegressor(
boosting_type='gbdt', # ブースティングアルゴリズム:gbdt 一般
num_leaves=31, # 1本の決定木で作れる「葉ノード」の最大数 (=2^max_depth が理想)
max_depth=-1, # 木の深さ(-1は制限なし)
learning_rate=0.04, # 学習率
n_estimators=1000, # ブースティングする木の本数(=弱学習器の数)
subsample_for_bin=200000, # 特徴量のヒストグラム(binning)を作成するために使用するデータ数の上限
objective='regression', # 回帰タスク用の目的関数
class_weight=None, # 各クラスの重み (回帰モデルでは設定不要)
min_split_gain=0.0, # 最小の利得
min_child_weight=0.001, # 目的関数の重み合計
min_child_samples=3, # 1つの葉に含まれる最低限のデータ数
verbosity=-1, # ログ出力レベル(-1: 無効, 0: 警告, 1: 情報)
)
# 学習(early_stopping をサポート)
model.fit(
X_train, y_train, # 学習用の特徴量
eval_set=[(X_test, y_test)],# 検証データ
eval_metric='rmse', # 評価指標:平方根平均二乗誤差
callbacks=[ # 検証して結果が改善しなければ学習を打ち切る回数
early_stopping(stopping_rounds=10)
],
)
return model
# ------------------------------------------------------------
# 動作確認
# ------------------------------------------------------------
# ガチャ抽選結果CSVファイルのPath設定
file_path = 'data/gacha_result.csv'
# ガチャ結果を DataFrame に読込
gacha_result_df = load_gacha_result_df(file_path)
# 学習データを作成
learn_df = create_learn_df(gacha_result_df, "Id", 10)
# 学習モデルを作成
learn_model = create_learn_model(learn_df) ★追加
4.予測元となるデータの作成
予測元データを作成する下記メソッド(create_latest_hist_df)にて、直近10件のガチャ結果を取得します。
【予測元データの作成処理】
import numpy as np
# ------------------------------------------------------------
# 直近N回の抽選結果履歴を作成
# target :参照するカラム名
# hist_num:参照する直近の履歴数
# ------------------------------------------------------------
def create_latest_hist_df(data_df, target, hist_num):
# 抽選結果のデータを抽出
data_df = data_df[target]
# 抽選結果履歴ヘッダの作成
hist_header = create_hist_header(hist_num)
# 直近の抽選結果の履歴を取得
latest_hist = np.array(data_df[- hist_num:][::-1]).reshape(1, -1)
# 直近の抽選結果を履歴をDataFrame化
latest_hist_df = pd.DataFrame(latest_hist, columns=hist_header)
return latest_hist_df
# ------------------------------------------------------------
# 動作確認
# ------------------------------------------------------------
# ガチャ抽選結果CSVファイルのPath設定
file_path = 'data/gacha_result.csv'
# ガチャ結果を DataFrame に読込
gacha_result_df = load_gacha_result_df(file_path)
# 予測させるために直近N回の抽選結果履歴を作成
latest_hist_df = create_latest_hist_df(gacha_result_df, "Id", 10)
# 内容確認 ※処理結果を参照
display(latest_hist_df)
正常に処理されれば、直近10件のガチャ結果が下記のような DataFrame になります。
※ここの「Bef_[N]_Result」が 直近 N 回前のガチャ結果の ID となります。
【処理結果】

5.予測の実行と確認
予測処理を行う下記メソッド(gacha_lot_predict)にて、作成した予測元データを学習モデルに渡して、次にくるガチャ結果を予測します。
【予測処理】
# ------------------------------------------------------------
# 予測処理
# data_df :入力データ
# target :予測する項目
# hist_num:特徴値にする参照履歴数
# ------------------------------------------------------------
def gacha_lot_predict(data_df, target, hist_num):
# 学習データを作成
learn_df = create_learn_df(data_df, target, hist_num)
# 学習モデルを作成
learn_model = create_learn_model(learn_df)
# 予測させるために直近N回の抽選結果履歴を作成
latest_hist_df = create_latest_hist_df(data_df, target, hist_num)
# 予測実行
pred_result = learn_model.predict(latest_hist_df)
# 予測結果を返却 ※予測結果が float型 なので int型 にキャスト
return int(round(pred_result[0]))
# ------------------------------------------------------------
# 動作確認
# ------------------------------------------------------------
# ガチャ抽選結果CSVファイルのPath設定
file_path = 'data/gacha_result.csv'
# 参照する履歴数の設定
hist_num = 10
# ガチャ結果を DataFrame に読込
gacha_result_df = load_gacha_result_df(file_path)
# 予測処理
pred_id = gacha_lot_predict(gacha_result_df, "Id", hist_num)
# 予測結果に紐づくロット情報を取得
lot_dict = {item[0]: item for item in lot_2nd_all_list}
lot_result = lot_dict.get(pred_id)
# 内容確認 ※処理結果を参照
display(lot_result)
正常に処理されれば、下記のように次に抽選されるロットが予測されます。
【処理結果】
予測まで出来れば、後はガチャを実行して、結果が一致するかを確認していきます。
これまでの処理をガチャの予測処理メソッド(gacha_predict)に纏めて、ガチャ実行メソッド(gacha_lottery)の結果と比較して予測結果が正しいかを確認します。
※前述していますが、今回はガチャの排出結果の予測がメインとなります。
そのため検証用ガチャの実行メソッド(gacha_predict)の詳細は省略しています。
【抽選予測&抽選結果確認】
# ------------------------------------------------------------
# ガチャの予測処理
# ------------------------------------------------------------
def gacha_predict():
# ガチャ抽選結果CSVファイルのPath設定
file_path = 'data/gacha_result.csv'
# 参照する履歴数
hist_num = 10
# ガチャ結果を DataFrame に読込
gacha_result_df = load_gacha_result_df(file_path)
# 予測処理
pred_id = gacha_lot_predict(gacha_result_df, "Id", hist_num)
# 予測結果に紐づくロット情報を取得
lot_dict = {item[0]: item for item in lot_2nd_all_list}
lot_result = lot_dict.get(pred_id)
return lot_result
# ------------------------------------------------------------
# 動作確認
# ------------------------------------------------------------
# ガチャの予測
predict_result = gacha_predict()
# 内容確認 ※処理結果を参照
print("◆抽選予測")
display(predict_result)
# ガチャの実行 ※検証用ガチャの実行メソッド(ここでは省略)
result = gacha_lottery()
# 内容確認 ※処理結果を参照
print("◆抽選結果")
display(result)
正常に処理されれば、下記のように次に予測されるロットと抽選されたロットの両方が確認できます。
【処理結果】

あとがき
結果を見ると分かりますが、予測されるロットと実行結果のロットが一致していません。
理屈的にガチャのような抽選処理はほぼ完全な乱数で行われているため、統計的に方向性が取れず、予測はほぼ出来ないそうです。
ここで気になる点としては、実際の予測の正解率はどの程度だったのかという事です。
処理をよく見るとモデルを作成する処理(create_learn_model)で、約10000件強の学習データの8割を学習に、2割を検証に当てて正解率が高くなるモデルを構築しているのが解ります。
このモデル作成時の処理ログが下記となります。
【モデル作成時の処理ログ】

作成モデルのスコア(rmse)が8.92833と表示されているのが解ります。
これは1件正解するのに平均8.9回予測が外れました・・・という意味となるそうです。
これより正解率は概ね下記となります。
正解率(%) = 1 / (1 + 8.9) × 100 = 10.101・・・
つまり約10%程度は予測が当たるという事になります。
実際のガチャの場合、ロットがもっと多くなるので正解率は更に下がるでしょう。
理論上は完全な乱数だと予測することは不可能だそうですが、機械的に完全な乱数を生成できているかと言えば疑問が残ります。
処理が重たくなるのでこれ以上はやりませんが、もっと学習データの件数を増やしていけば正解率は更に上がるかもしれません。
以上で「AI の機械学習アルゴリズム(LightGBM)を使って、ガチャ結果を予測してみた」は終了となります。
最後まで読んでいただき、ありがとうございました。
コメントはありません。