ブログ
これまでに経験してきたプロジェクトで気になる技術の情報を紹介していきます。
画像から表を自動で抽出!PaddleOCR × Pandas で簡単データ化
 Kitaru
1 year
Kitaru
1 year

はじめに
スキャンした請求書、帳票、領収書など「画像として保存された表データ」を、手作業で Excel に入力していませんか?
本記事では、Python ライブラリ PaddleOCR の中のドキュメント構造解析機能である PP-StructureV3 を使って、画像内の表を自動で読み取り、pandas の DataFrame 形式で取り出す方法 を解説します。
なぜ PaddleOCR を選んだのか?
OCR ライブラリには Tesseract OCR や EasyOCR などもありますが、これらを試した結果、PaddleOCR が最も文字認識の精度が高く、文字列検出能力に優れていました。
また、表構造を自動で認識し HTML 形式で出力できる機能(PP-StructureV3)は、他の OCR ライブラリにはなく、PaddleOCR を採用しています。
使用パッケージ
| パッケージ | 用途・説明 |
|---|---|
paddleocr |
OCR 処理を行うツール群。文字認識や文書構造解析(PP-StructureV3)により表やレイアウト検出も可能 |
paddlepaddle |
PaddleOCR の動作に必要な深層学習フレームワーク。PaddleOCR の演算エンジンとして機能する |
setuptools |
Python のモジュールを構築・配布するための支援ツール。未インストール時は PaddleOCR 実行時にエラーが発生 |
pandas |
表形式データの操作や変換を行うためのデータ分析ライブラリ。HTML テーブルの読み込みなどに利用 |
jupyter |
コードの実行や可視化を対話的に行える開発環境。実験や検証、デバッグに便利 |
環境構築(Windows + CPU 版の例)
Python バージョンの確認
まず、Python のバージョン 3.9~3.13 がインストールされていることを確認してください。
ターミナル(PowerShell)で以下のコマンドを実行します。
PS> python --version Python 3.13.3
仮想環境の作成と有効化
他のプロジェクトと依存関係が混ざらないよう、仮想環境を作成します。
# 仮想環境の作成 PS> python -m venv .venv # 仮想環境の有効化 PS> .\.venv\Scripts\activate (.venv) PS>
必要なパッケージのインストール
以下の順番で必要なパッケージをインストールしていきます。
pip のアップグレード
(.venv) PS> python -m pip install --upgrade pip
PaddlePaddle(CPU 版)
(.venv) PS> python -m pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
ℹ️ GPU 版や他の OS でのインストール方法は、以下の公式ページを参照してください:
https://www.paddlepaddle.org.cn/en/install/quick?docurl=/documentation/docs/en/develop/install/pip/windows-pip_en.html
PaddleOCR
(.venv) PS> python -m pip install paddleocr
setuptools
(.venv) PS> python -m pip install setuptools
開発補助ツール(任意)のインストール
以下は PaddleOCR の実行に必須ではありませんが、作業効率を上げるためにインストールしておくと便利です。
Jupyter Notebook(ノート形式での実行・デバッグ用)
(.venv) PS> python -m pip install notebook
pandas(OCR 結果を DataFrame として扱いたい場合)
(.venv) PS> python -m pip install pandas
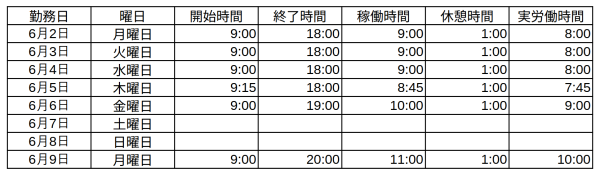
検証画像
以下は勤怠の画像ファイルです。
この画像を解析して DataFrame に変換します。
表抽出の実行コード(最小構成)
以下のコードで、画像内の表を自動的に抽出・解析し、DataFrame に変換できます。
from paddleocr import PPStructureV3
import pandas as pd
# 表構造認識用の OCR エンジンを初期化
engine = PPStructureV3()
# 処理対象の画像パスを指定(表が写っている画像)
img_path = 'kintai.png'
# 画像から表構造を解析(表があると判断された領域ごとに結果が返る)
results = engine.predict(img_path)
# 最初の表領域の情報を取り出す(通常1画像に1表のケースが多いため)
res = results[0]
# 表の HTML 構造を取得(PPStructureV3 が出力する推定結果)
table_res_list = res.get('table_res_list', [])
# 表構造 HTML を取得(予測結果があれば1つ目を使用)
html = table_res_list[0].get('pred_html', '') if table_res_list else ''
# HTML 構造が取得できていれば、それを pandas で DataFrame に変換
if html:
try:
# pandas.read_html は HTMLの table タグを自動で解析して DataFrame に変換する
dfs = pd.read_html(html)
df = dfs[0] # 最初のテーブルだけ取り出す(通常1つ)
display(df) # JupyterでDataFrameをきれいに表示
except Exception as e:
print("HTML 解析中にエラーが発生しました:")
print(e)
else:
print("表のHTML構造が取得できませんでした。")
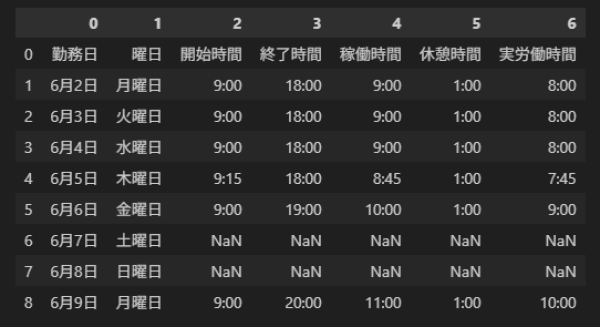
実行結果
display により DataFrame の内容が下記のように出力されます。
解説のポイント
PPStructureV3 とは?
- PaddleOCR が提供する表構造解析用の OCR エンジン
- 画像内のテキストだけでなく、セル・行・列といった表の構造も認識
- 認識結果を HTML 形式で出力可能
table_res_list とは?
- PPStructureV3 の
predict()が返す結果に含まれるキー - 画像内に存在する各表の解析結果を格納したリスト
table_res_list の構造
'table_res_list': [
{
'cell_box_list': [ ... ], # 各セルの座標(矩形)
'neighbor_texts': '', # 周辺テキスト(未使用/空)
'pred_html': '...', # 表のHTML構造(DataFrame化に使用)
'table_ocr_pred': {
'rec_boxes': [ ... ], # 各テキストのバウンディングボックス
'rec_polys': [ ... ], # テキストの多角形領域
'rec_scores': [ ... ], # テキストごとの信頼度(0〜1)
'rec_texts': [ ... ], # 認識された文字列
},
'table_region_id': 1 # 複数表がある場合の識別ID
}
]
各フィールドの補足説明
cell_box_list:
各セルの 矩形領域(座標)情報 が含まれています。
表の物理的なレイアウト(セルの位置・サイズ)を再構築する際に利用できます。pred_html:
予測された HTML 形式の表構造です。
pandas.read_html()にそのまま渡して、DataFrame に変換できます。table_ocr_pred:
OCR の生出力が格納されています。
各セル内の文字について、位置情報・内容・信頼度 などの詳細な情報を取得可能です。
pandas.read_html の強み
- HTML の
tableタグを自動的に解析して、DataFrame に変換できます。 rowspanやcolspanによる結合セルにも対応しています。- Jupyter Notebook 上で、表形式として簡単に表示・操作が可能です。
注意点
- GPU が搭載されていない低スペックな PC では、画像解析に数分かかる場合があります。
pandas.read_html()を使用すると、HTML テーブル内でrowspanやcolspanによって結合されているセルも、自動的に分割されます。そのため、DataFrame 上では通常の行・列として扱われる形になります。- 結合セルの構造を正確に再現したい場合や、細かく制御したい場合には、
BeautifulSoup
などを用いて手動で処理する必要があります。 - PaddleOCR が出力する HTML は、あくまで予測結果です。読み取り精度には限界があります(手動補正も必要になることがあります)
- 表や文字列がうまく検出されない場合は、画像の前処理(解像度の向上やノイズ除去など)を行うことで、精度が改善することがあります。
応用:DataFrame を Excel に保存
認識された表は、以下のようにして Excel ファイルとして保存できます。
df.to_excel('output.xlsx', index=False)
おわりに
PaddleOCR の表構造解析機能(PPStructureV3)を活用することで、次のような処理が可能になります:
- 画像内の表を自動的に検出・解析
- 表構造を HTML 形式で取得
- HTML を pandas で読み取り、Excel や CSV 形式に変換
これにより、帳票処理やレポート集計といった業務の自動化・効率化が実現できます。
コメントはありません。